Welcome to Auth0 Fine-Grained Authorization
Auth0 Fine-Grained Authorization enables developers to design authorization models, from coarse grained to fine-grained, in a way that's centralized, flexible, fast, scalable, and easy to use.
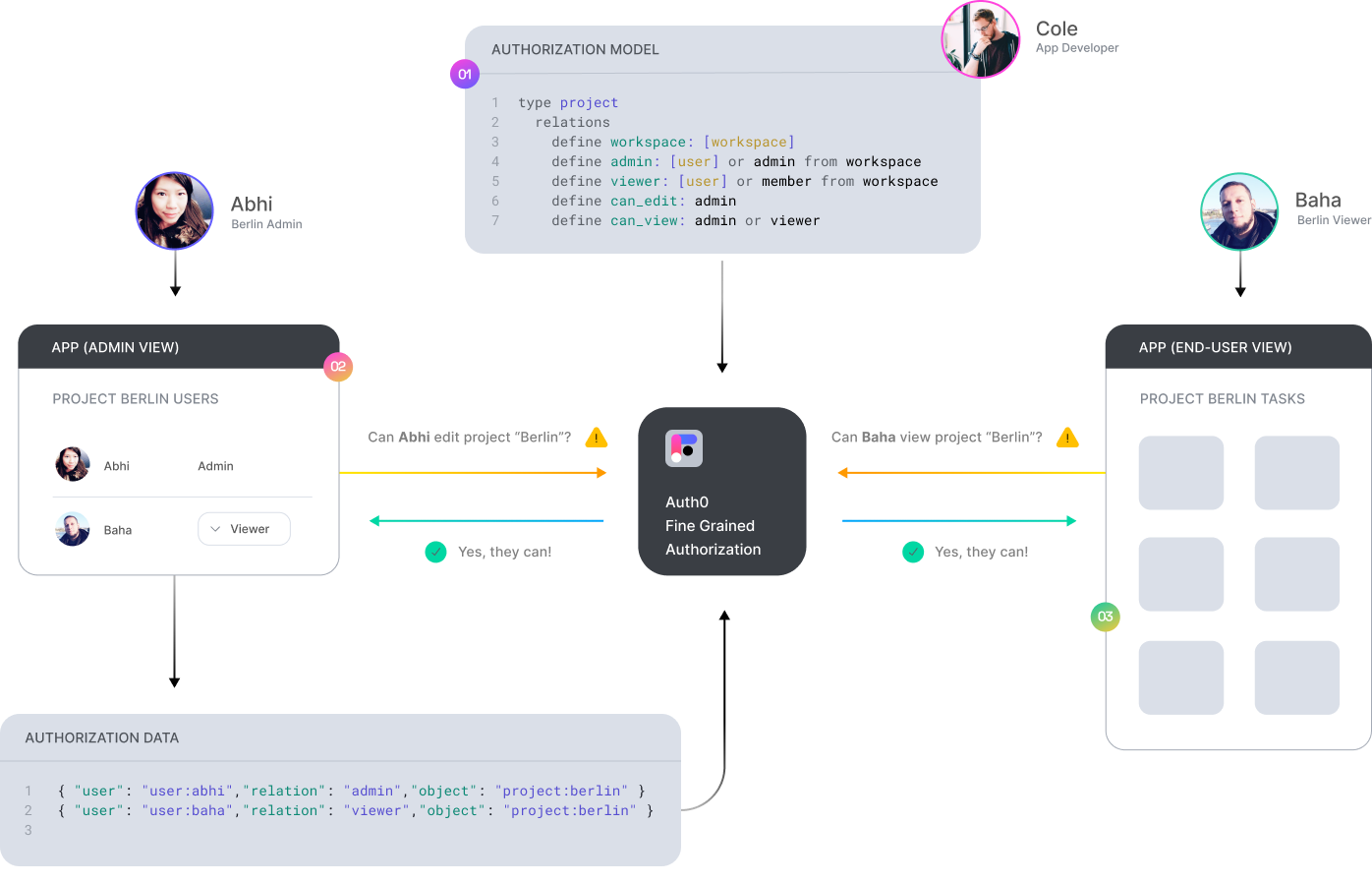
Authorization for your app in 3 steps
Define Your Authorization Model
Learn to define an authorization model via step-by-step guides and examples.
Getting started →Write Your Authorization Data
Learn to programmatically write authorization related data to Auth0 FGA
Overview →Add Authorization to Your API
Learn how to update your API to check a user's permissions before certain actions
Overview →Advanced Features
Advanced Modeling
Learn how real-world use cases can be modeled with Auth0 FGA
API Documentation
Learn how to use the Auth0 FGA API to programmatically perform any task